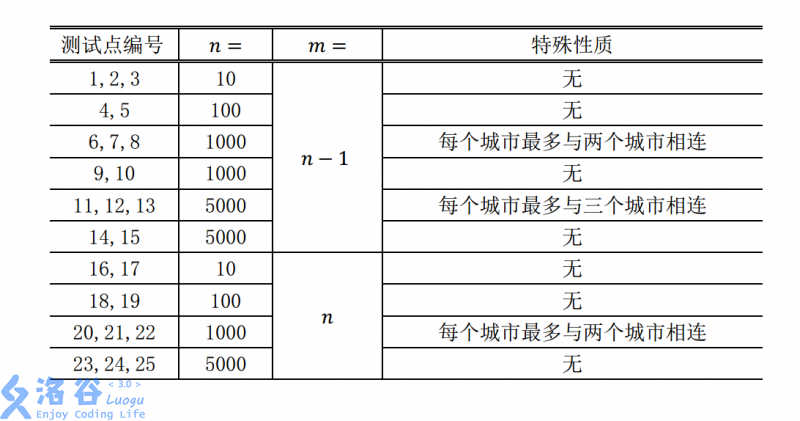
目录
样例解析
样例 1:树 (
输入:
6 5
1 3
2 3
2 5
3 4
4 6分析: 这是一个简单的树结构。
- 起点固定为 1(为了字典序最小)。
- 1 的邻居只有 3,去 3。
- 3 的邻居有 2 和 4。2 < 4,先去 2。
- 2 的邻居有 5。去 5。
- 5 无路可走,回溯到 2,回溯到 3。
- 3 的下一个邻居是 4。去 4。
- 4 的邻居有 6。去 6。 结果: 1 3 2 5 4 6
Graphviz 图示 (Sample 1)
图中红色实线箭头表示实际前进的路径,数字标签表示访问顺序。
digraph G {
label = "Sample 1: Tree Structure (m = n-1)\nResult: 1 3 2 5 4 6";
labelloc = "t";
node [shape=circle, style=filled, fillcolor=lightblue];
// 强制层级,使图看起来像一棵树
{rank=same; 1}
{rank=same; 3}
{rank=same; 2; 4}
{rank=same; 5; 6}
// 节点定义
1; 2; 3; 4; 5; 6;
// 边定义
// 红色箭头表示 DFS 首次访问路径
1 -> 3 [color=red, label="1", fontcolor=red, penwidth=2.0];
// 3 的子节点是 2 和 4,因为 2 < 4,先走 2
3 -> 2 [color=red, label="2", fontcolor=red, penwidth=2.0];
// 2 的子节点是 5
2 -> 5 [color=red, label="3", fontcolor=red, penwidth=2.0];
// 回溯后,从 3 走到 4
3 -> 4 [color=red, label="4", fontcolor=red, penwidth=2.0];
// 4 的子节点是 6
4 -> 6 [color=red, label="5", fontcolor=red, penwidth=2.0];
// 辅助隐形边辅助布局(可选)
edge [style=invis];
2 -> 4;
}
样例 2:基环树 (
输入:
6 6
1 3
2 3
2 5
3 4
4 5
4 6分析: 图包含一个环:2-3-4-5-2。
- 1 -> 3。
- 在节点 3,邻居有 2 和 4。显然 2 < 4,先去 2。
- 在节点 2,邻居有 5。
- 关键决策:如果我们现在去 5,路径是
1 3 2 5 ...。 - 如果我们不去 5(回溯),而是回到 3 走另一条路 4,路径是
1 3 2 ... 4。 - 比较这两个选择:如果不走 2->5,下一次访问的新节点将是 4(从3走过去)。如果走 2->5,下一次是 5。
- 因为 4 < 5,所以我们在节点 2 应该选择回溯,暂时放弃边 (2,5)。这相当于在逻辑上断开了环上的 (2,5) 边。
- 关键决策:如果我们现在去 5,路径是
- 回溯到 3,去 4。
- 在节点 4,邻居有 5 和 6。5 < 6,去 5。
- 在节点 5,邻居有 2,但 2 已访问,回溯。
- 回到 4,去 6。 结果: 1 3 2 4 5 6
Graphviz 图示 (Sample 2)
图中展示了环结构。红色实线是实际生成的 DFS 树,灰色虚线表示那条存在但未被用来“首次访问”的边(即逻辑断开的边)。
digraph G {
label = "Sample 2: Unicyclic Graph (m = n)\nCycle: 2-3-4-5-2\nResult: 1 3 2 4 5 6";
labelloc = "t";
// 使用 neato 布局以更好地展示环
layout = dot;
node [shape=circle, style=filled, fillcolor=lightyellow];
// 节点
1 [xlabel="Start"];
3;
2;
4;
5;
6;
// 路径:1 -> 3
1 -> 3 [color=red, label="①", fontcolor=red, penwidth=2.0];
// 路径:3 -> 2 (因为 2 < 4)
3 -> 2 [color=red, label="②", fontcolor=red, penwidth=2.0];
// 在节点 2,虽然有边连向 5,但为了更早访问到 4 (从3那边),
// 我们选择不走 2->5,而是回溯。
// 这条边 (2, 5) 在 DFS 树中没有被使用(或者理解为回边)
2 -> 5 [dir=none, style=dashed, color=grey, label="Backtracking\nDecision:\n4 < 5", fontcolor=grey];
// 回溯到 3 后,走 3 -> 4
3 -> 4 [color=red, label="③", fontcolor=red, penwidth=2.0];
// 在节点 4,先走 5 (5 < 6)
4 -> 5 [color=red, label="④", fontcolor=red, penwidth=2.0];
// 回溯到 4 后,走 4 -> 6
4 -> 6 [color=red, label="⑤", fontcolor=red, penwidth=2.0];
// 物理连接关系补充说明:
// 实际上 2-5 是相连的,4-5 也是相连的。
// 在这里 4->5 是树边,2->5 是非树边。
}
关键逻辑解释
在图 2 中,最让人困惑的一步是:为什么到了 2 之后不继续走到 5?
这是因为这道题要求字典序最小。 当我们在环上时,我们实际上是在寻找一个位置“断开”环,使得生成的序列最优。 在节点 2 时,我们面临两个潜在的“下一个新节点”:
- 直接走 (2, 5),下一个记录的数是 5。
- 回溯到 3,走 (3, 4),下一个记录的数是 4。
因为 4 < 5,所以策略告诉我们:不要走 (2, 5),赶紧回溯去走 (3, 4) 吧!这样我们就能在序列的更前面填入更小的数字 4。
题目解析
要从 题目描述 推导出“
1. 数据的拓扑结构:为什么是“基环树”?
首先,从图论的基础定义来看:
且连通:这必然是一棵树。树没有环,路径是唯一的(不走回头路的情况下)。 且连通:这相当于在 条边的树上,多加了一条边。 - 在一棵树上任意连接两个不相邻的节点,必然会形成且仅形成一个环。
- 这种结构被称为 “基环树” (Unicyclic Graph),也就是你理解的“带有一个环的树”。
2. 旅行规则:为什么等价于生成树?
这是理解问题的关键。让我们仔细拆解题目中的小 Y 的旅行方案:
规则 A: “从起点开始,每次可以选择一条与当前城市相连的道路,走向一个没有去过的城市。”
规则 B: “或者沿着第一次访问该城市时经过的道路后退到上一个城市。”
规则 C: “每个城市都被访问到。”
这三条规则合起来,实际上完整描述了一个 DFS(深度优先搜索) 的过程:
- 规则 A 对应 DFS 的“递归进入(Traverse)”:只要有未访问的邻居,就继续深入。
- 规则 B 对应 DFS 的“回溯(Backtrack)”:当走到死胡同(所有邻居都去过了),就退回上一步。
- 规则 C 意味着这个 DFS 遍历必须覆盖图中的所有
个点。
结论:
小 Y 走过的所有“走向没有去过的城市”的边,实际上构成了原图的一棵 生成树 (Spanning Tree)。
- 原图有
个点。 - 要访问所有
个点,且不重复记录(只记录第一次到达),你需要且仅需要经过 条边来“发现”这些点。 - 这
条边构成的结构,就是一棵树。
3. 核心推导:为什么要“断掉一条边”?
现在我们将 1(原图结构) 和 2(行走轨迹) 结合起来:
- 原图:有
个点, 条边(包含一个环)。 - 实际有效的行走路径(生成树):使用了
条边。
数学计算:
这意味着,在小 Y 的整个旅行过程中,原图中必然有且仅有一条边,从来没有被用来“走向一个没有去过的城市”。
这条被“遗弃”的边有以下性质:
- 它必须在环上。
- 如果你“遗弃”的边不在环上(即它是树枝上的边,也就是桥),那么图就会断开,你就无法访问所有节点了。只有断开环上的边,图依然保持连通。
- 它的逻辑等价性。
- 既然这条边在遍历中没有起到“发现新节点”的作用,那么对于生成最终的访问序列来说,这条边存不存在是完全一样的。
- 因此,我们可以假装这条边不存在。
总结:逻辑闭环
- 结构:
的连通图是一个带有一个环的树。 - 规则:题目要求的遍历方式本质是寻找一棵生成树。
- 冲突:生成树只需要
条边,而图有 条边。 - 解决:必然有一条边多余。为了保持连通,这条多余的边只能是环上的某一条。
- 策略:既然必然要废弃环上的一条边,为了找到字典序最小的序列,我们只需要枚举环上的每一条边,尝试将其暂时删除,然后按照
的贪心策略(每次走编号最小的邻居)跑一遍,最后取最优解即可。
简单的图示帮助理解
假设有这样一个基环树:
代码段
graph TD
1((1)) --- 2((2))
2 --- 3((3))
3 --- 4((4))
4 --- 2
2 --- 5((5))
- 环是: 2 - 3 - 4 - 2
- 总边数: 5 条。
- 节点数: 5 个。
小 Y 要访问所有点。当她走到环的入口(节点 2)时,她必须决定是先去 3 还是先去 4。
- 如果她选择了
,那么边 实际上就没有被用来“发现新节点”(当她从 4 想要去 2 时,发现 2 已经去过了,只能回溯)。这等同于把 断开了。 - 如果她选择了
,这等同于把 断开了。
因为
代码
/**
* Author by Rainboy blog: https://rainboylv.com github : https://github.com/rainboylvx
* rbook: -> https://rbook.roj.ac.cn https://rbook2.roj.ac.cn
* date: 2026-01-10 08:58:46
*/
#include <bits/stdc++.h>
#include <vector>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const int maxn = 5005;
const int maxe = 4e6+5;
const int mod = 1e9+7;
int n,m;
int a[maxn];
int del_edge = 0; //枚举删除的边
typedef std::pair<int,int> edge;
std::vector<edge> adj[maxn];
void init(){
std::cin >> n >> m;
for(int i = 1;i <= m ;++i ) // i: 1->m
{
int u,v;
std::cin >> u >> v;
// debug
// std::cout << "id : " << i << " -> " << u << " " << v ; std::cout << "\n";
//next点 ,边的编号
adj[u].push_back({v,i});
adj[v].push_back({u,i});
}
for(int i = 1;i <= n ;++i ) // i: 1->n
{
std::sort(adj[i].begin(),adj[i].end());
}
}
std::vector<int> ans;
std::vector<int> tmp_ans;
std::vector<int> loop; //记录环上的边
// 回溯法找环: 原理: 找到环上的点,立刻回溯
bool vis[maxn];
int dfs_find_loop(int u,int fa) {
// 表示找到了, 返回环上的其实点
if( vis[u] ) return u;
vis[u] = 1;
for(auto [v,id] : adj[u]) {
if( v == fa) continue;
int loop_first = dfs_find_loop(v, u);
if( loop_first ) {
loop.push_back(id);
vis[u] = 2; //标记是环上的点
return u == loop_first ? 0 : loop_first;
}
}
return 0; //表示没有找到
}
void dfs(int u,int fa) {
tmp_ans.push_back(u);
for( auto [v,id] : adj[u]) {
if( id == del_edge) continue;
if( v == fa) continue;
dfs(v,u);
}
}
// ans 里面存的序列 比 tmp_ans 大
// 字典序比较
bool compare_ans() {
if( ans.size() == 0 ) return 1;
for(int i = 0 ; i < ans.size();i++) {
if( ans[i] > tmp_ans[i])
return 1;
else if( ans[i] < tmp_ans[i])
return 0;
}
return 0;
}
signed main () {
ios::sync_with_stdio(false); cin.tie(0);
init();
// 找环上的边
// 1. topsort
// 2. dfs法 -- >这里使用
if( m == n-1) {
dfs(1,0);
for( auto u : tmp_ans) {
std::cout << u << " ";
}
return 0;
}
dfs_find_loop(1, 0);
// debug: 输出环上的边
// for( auto & i : loop ) {
// std::cout << "id : " << i << endl;
// }
for( auto i : loop ) {
tmp_ans.clear();
del_edge = i;
dfs(1,0);
//debug
// std::cout <<" del -> " << i << "\n";
// for( auto u : tmp_ans) std::cout << u << " ";
// std::cout << "\n";
if( compare_ans()) std::swap(tmp_ans,ans);
// for( auto u : ans) std::cout << u << " ";
// std::cout << "\n";
// std::cout << "\n";
// std::cout << "\n";
}
for( auto u : ans) std::cout << u << " ";
return 0;
}